Estimated Time: 15-30 minutesConfigure your first data ingestion pipeline and start bringing data from your various sources into the 5X platform.
Ready to ingest data
With your app connections now configured, you’re now ready to set up your first data ingestion pipeline and start bringing data into your warehouse.What is data ingestion?
Data ingestion is the process of bringing raw data from external systems into your warehouse, standardizing its format and centralizing it for further use. Whether you’re pulling sales data from a CRM, logs from internal databases, or campaign performance from a marketing platform, 5X enables you to ingest with minimal engineering effort. The 5X platform provides a managed, secure, and no-code user experience for data ingestion, eliminating the complexity of managing multiple data integration tools.Your ingestion toolkit: 600+ connectors
5X supports a broad catalog of 600+ out-of-the-box connectors, including:Applications
Popular SaaS applications:
- Salesforce, HubSpot, NetSuite
- Zendesk, Shopify, Stripe
- Slack, Jira, Confluence
Databases
All major database systems:
- PostgreSQL, MySQL, MongoDB
- Redshift, Snowflake, BigQuery
- Oracle, SQL Server, Cassandra
Analytics & Marketing
Analytics and marketing platforms:
- Google Analytics, Facebook Ads
- Mixpanel, Klaviyo, Mailchimp
- Adobe Analytics, LinkedIn Ads
File Storage
File and cloud storage:
- Google Sheets, Excel (via cloud)
- Amazon S3, Google Cloud Storage
- FTP, SFTP, Dropbox
If a connector is not available in our catalog, you can request custom connectors, which are typically delivered within days. You can also ingest from modern APIs or legacy sources using custom integration blueprints maintained by 5X.
Setting up your first ingestion pipeline
Let’s walk through creating your first data ingestion pipeline:1. Access the ingestion module
- Navigate to Ingestion
- Visit platform.5x.co and log into your workspace
- In the left sidebar, click on Ingestion
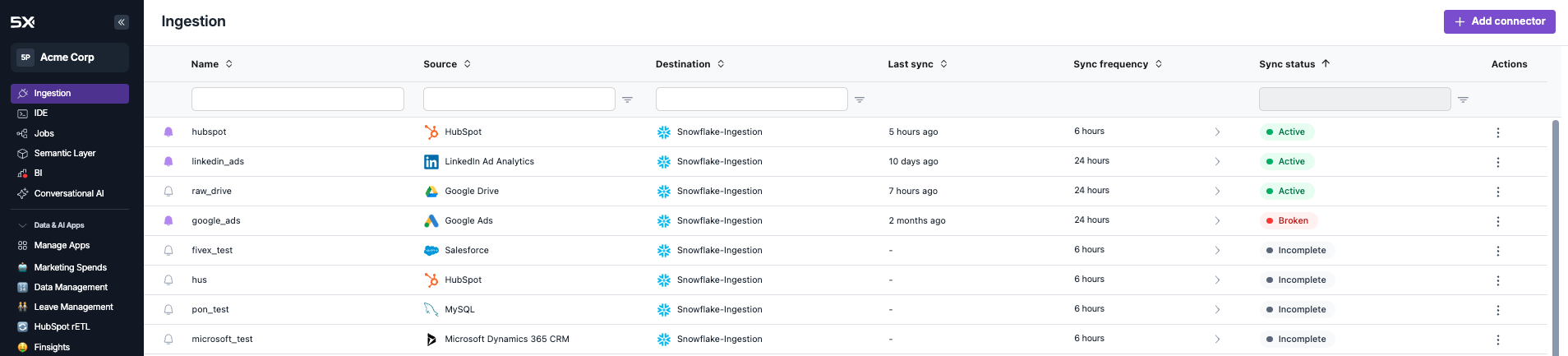
- Start New Connector Setup
- On the ingestion dashboard, click Add Connector to begin setup
2. Select your data source
- Choose from 600+ Connectors
- Use the search bar to find your desired source (e.g., “Google Sheets” or “Salesforce”)
- Browse by category: Applications, Databases, Analytics, File Storage
- Click the source card to begin the configuration process
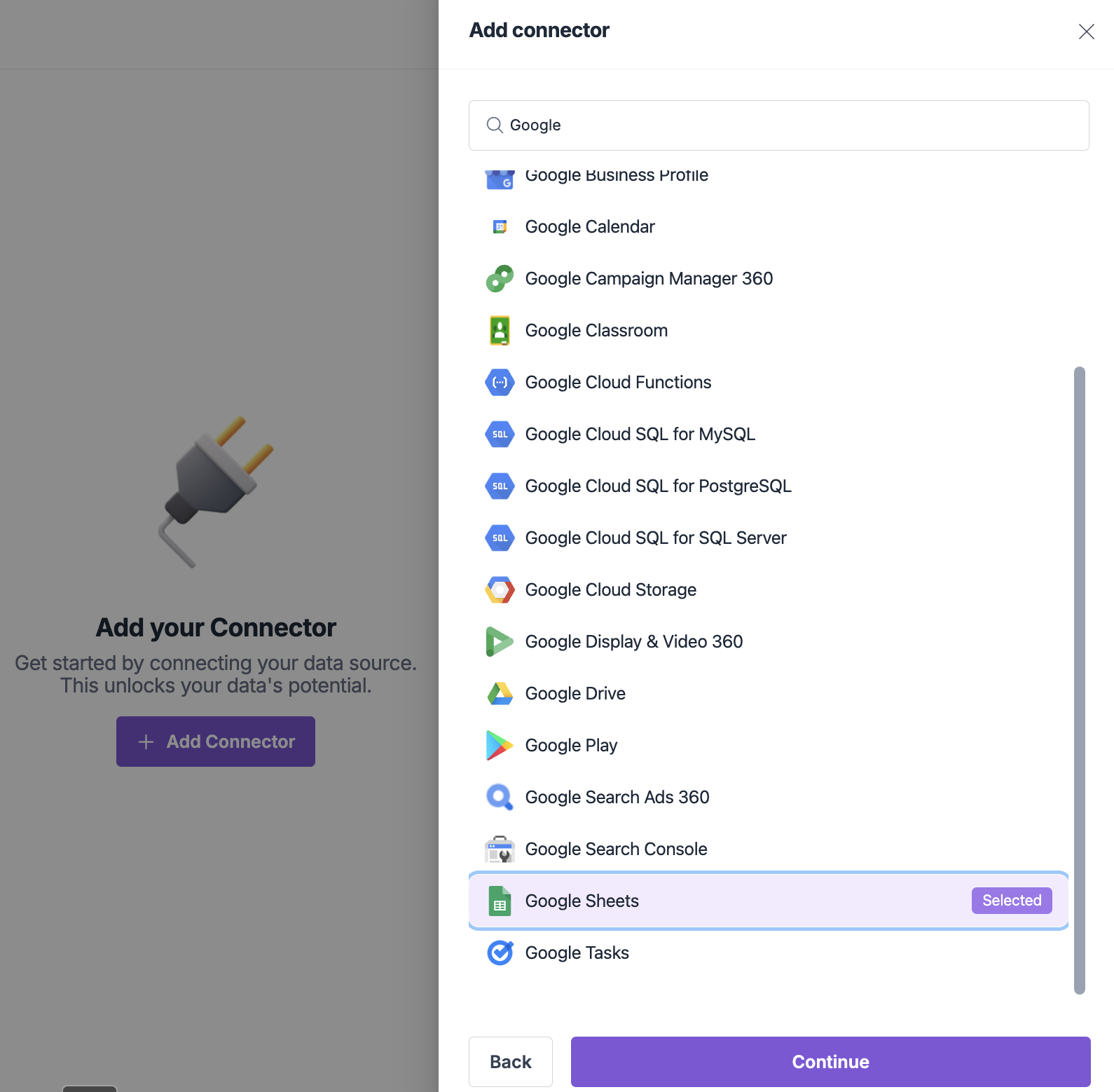
3. Configure your connector
The setup screen will prompt you for several fields. These vary by connector, but common fields include: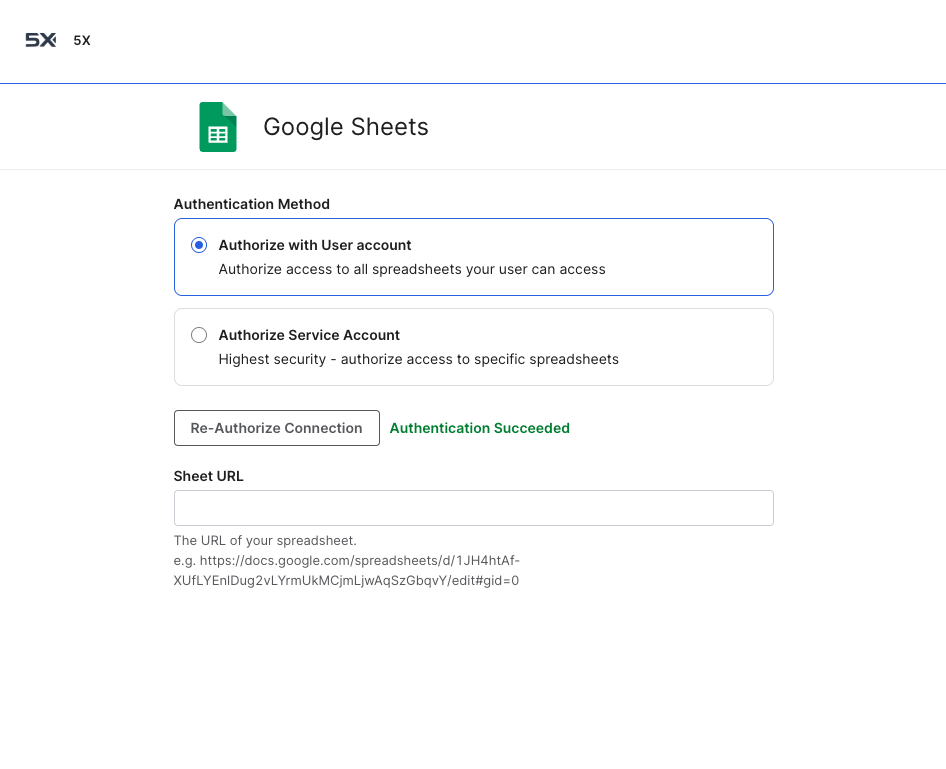
Basic Configuration
Basic Configuration
Required Information:
- Destination schema name: Choose where data will be written in your warehouse
- Connection parameters: Configure source-specific connection settings
- Data selection: Choose which objects, tables, or datasets to sync
- Additional settings: Configure any source-specific parameters as required
Authentication
Authentication
Authentication varies by connector type and may include:
- OAuth flows: Direct login with your account credentials
- API keys and tokens: Service account credentials or API authentication
- Database credentials: Username, password, and connection strings
- Certificate-based: Private keys or certificate files for secure connections
- Resource-specific access: Direct URLs or specific resource identifiers
Advanced Settings
Advanced Settings
Additional configuration options may include:
- Data filtering and transformation: Apply filters or basic transformations during ingestion
- Security settings: Configure data privacy and access controls
- Performance tuning: Optimize sync behavior for your specific use case
- Compliance features: Enable data governance and audit capabilities
Use descriptive destination schema names since they determine your connector names and where data lands in your warehouse. Good examples:
salesforce_crm, google_analytics, postgres_customers, shopify_orders. Avoid spaces and use underscores for multi-word schemas.4. Complete setup and start initial sync
-
Review Configuration
- Double-check all settings and authentication details
- Verify data selection and sync frequency
- Preview the sync configuration
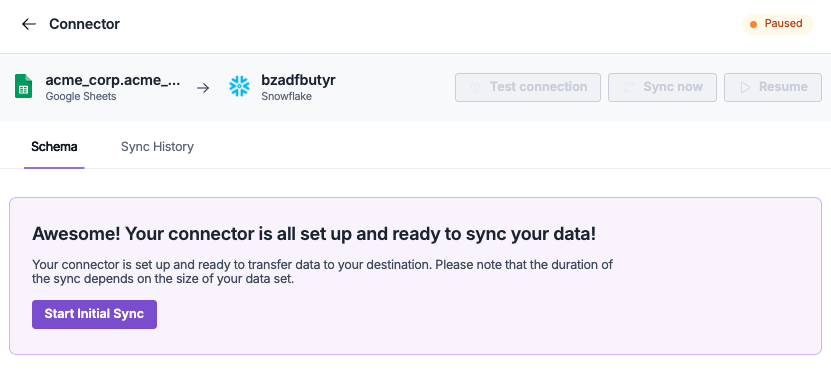
-
Trigger Initial Sync
- Click Continue through each configuration screen
- Once setup is complete, you’ll see a confirmation screen
- Click Start Initial Sync to begin your first data transfer
- The initial sync will run immediately to populate your warehouse with data
5. Manage sync settings and data selection
Once your connector is active, you can manage its sync behavior and data selection from the connector details page: Access Sync Settings:- From the ingestion dashboard, click on your connector name
- Or use the Actions menu to access connector settings
- Fixed Intervals: Choose from preset options (1 minute to 24 hours)
- CRON Expressions: Set custom schedules using CRON syntax
- Manual Sync: Trigger syncs on-demand using the “Sync now” button
- Use the Schema tab to manage which data gets synced
- Select or deselect entire tables with checkboxes
- Choose specific columns within each table
- Use search functionality to find specific tables quickly
- Toggle “Show selected tables” to focus on active data sources
- Test connection: Verify your source connection is working
- Sync now: Trigger an immediate sync outside the schedule
- Pause: Temporarily stop all syncing
- Monitor status: View real-time sync status and last sync time
Best practices for secure ingestion
Credential Management
Credential Management
Best Practices:
- Use service accounts instead of personal credentials when possible
- Rotate API keys and credentials regularly
- Apply principle of least privilege for data access
- Monitor credential usage and access patterns
Data Governance
Data Governance
Governance Recommendations:
- Hash or exclude sensitive fields (PII, financial data) during ingestion
- Set up data retention policies for ingested data
- Document data sources and their business purposes
- Regular review and audit of active connectors
Performance Optimization
Performance Optimization
Performance Tips:
- Choose appropriate sync frequencies based on data change rates
- Use incremental sync for large datasets
- Schedule resource-intensive syncs during off-peak hours
Troubleshooting common issues
Connection Failures
Connection Failures
Common Issues:
- Network connectivity problems
- Authentication failures (expired tokens, wrong credentials)
- Source system downtime or maintenance
- Firewall or security group restrictions
- Verify connection settings: Double-check host, port, and database names
- Test authentication: Ensure credentials are valid and have proper permissions
- Check network connectivity: Verify firewall rules and network access
- Monitor source system status: Check if the source system is operational
- Review error logs: Look for specific error messages in sync history
Data Quality Issues
Data Quality Issues
Common Problems:
- Data type mismatches between source and destination
- Unexpected null values in required fields
- Character encoding issues (special characters, unicode)
- Date format inconsistencies across systems
- Duplicate records or primary key violations
- Review data type mappings: Ensure compatible data types
- Implement data validation: Set up rules to catch quality issues
- Add data cleaning: Use transformations to standardize data
- Monitor data quality: Set up alerts for quality degradation
- Document data quirks: Note known issues and workarounds
What’s next?
With ingestion complete and your data flowing into the warehouse, you can now:Explore Data
Query and explore your ingested data using the integrated SQL editor
Invite Your Team
Add teammates and set up permissions for collaborative data work
Explore What's Next
Discover advanced features when you’re ready to go deeper
Continue to Step 6
Next: Explore your dataQuery and explore your ingested data using the integrated SQL editor to understand its structure and quality.